It’s a common problem: a game gets patched, the original hack/cheat author is nowhere to be found, and your favorite unauthorized modification to the game no longer works. Or, maybe you are an author of your own hacks, and your tired of all the pain and time wasted when the game or program your targeting is inevitably patched.
This article is meant to serve as a guide to assist the reader in solving the problems that come about when attempting to use or design assembly instructions injected into binaries that either have been patched or might get patched in the future. Whether you’ve never done this sort of thing before, or have been writing your own hacks for a bit, this article should prove useful in making your life a little bit easier, at least as far as getting your hacks up to date goes.
We’ll start off by discussing exactly why your injection-based hacks won’t work anymore after a targeted program gets patched, followed by how we can go about getting our hacks to work again. I’ll then be spending some time going over strategies we can follow to make our hacks more “update-proof”, how to identify injection sites likely to cause us problems, and more.
So, all of that being said, let’s get things rolling by taking a look at why, when a game gets patched, we can no longer inject our lovely hacks into that particular game or program anymore.
Why a Patch Breaks Hacks
The majority of games these days are delivered via some sort of centralized content delivery system such as Steam. As consumers, we tend to have little control over when patches for these games are delivered and applied to our local hard drives, and it can be rather difficult and time consuming to revert to earlier versions of the game. It follows, then, that a healthy dose of paranoia is appropriate in regards to the “health” of our hacks, and that we should be well prepared to deal with unexpected patches beforehand.
So, what is it that these binary hacks, such as ones powered by my Omnified framework, actually do? They change how a game or program behaves, and they do that by replacing a targeted assembly instruction found in the game’s process with a jmp statement that goes to our own code located in sandboxed memory.
The key phrase above is “targeted assembly instruction”. We need to be able to locate the correct instruction, or else problems will occur. An assembly instruction is targeted in several ways, the first way being by specifying its exact location in the binary with a particular offset being added to the base address of the executable.

This type of injection can be done via Cheat Engine like so:
If the particular instruction is not located at the address calculated by adding an offset to the game’s base address, then injection will fail. It will fail because of the very next line of code displayed in the first image of the two shown above, which ensures that the expected sequence of bytes exists at the address. If this assert statement is removed, then injection will of course succeed, but we’ll absolutely end up making the program crash instead, as we will be replacing an unknown assembly instruction with a different one (and if that doesn’t cause a crash, you’ve essentially won the lottery).
And this is the core problem that comes about when a game gets patched: targeted assembly instructions will almost always (though not 100% of the time) no longer be where they previously were within the game’s loaded binary. This revelation should then make the solution to fixing our broken hacks relatively clear: we must re-locate our previously targeted assembly instructions, and retarget them at their new addresses.
This is not the only reason why a patch might break our hacks, but it’s the most prevalent reason. Later on in the article, when we’re going over how to make our hacks more “patch-proof”, we’ll touch on all the other reasons as to why a patch might break our hacks. Until then, we’ll focus on the most frequent reason behind the breakage of our lovely hacks.
What’s the second method of targeting an assembly instruction?
A particular assembly instruction can also be located using a recorded unique array of bytes. This is achieved by figuring out whether the instruction, in conjunction with the other instructions that surround it, make up a sequence of bytes that’s unique across the executable’s entire memory footprint. If so, we can find it again, and our success will be independent of the instruction’s exact location.
Like the first method, this form of injection can also be done using Cheat Engine, and it is done like so:
This method is by no means immune to the problems that come about from a game getting patched, though it can often be more resistant to breaking. We will get into the reasons why a little bit later on, as we will actually be making use of the unique array of bytes technique in order to make it possible to fix our hacks following an update, even though I only use the first method of assembly instruction targeting.
I never inject my hacks using the unique array of bytes approach as it is incredibly slow in comparison to using the instruction’s specific address in memory. An Omnified game is typically composed of many separate injections, and having to scan for a unique array of bytes for each one is way too slow.
That being said, targeting assembly instructions using the first method requires discipline, or else you will be absolutely screwed when a game ends up getting patched. The level of discipline required, as well as why we’ll be screwed without said discipline, will be made clear to the reader a little bit later on in this article.
Why a Patch Moves Instructions Around
In the previous section, we identified the main reason why a patch will break our hacks: because the assembly instructions our hacks are targeting are no longer in the same place they were before. So, why is that?
In order for us to know why instructions get reshuffled following a patch, it helps to understand what these executables we’re playing around with are and how they’re made.
To put it simply, an .EXE file, at least on a Windows machine, is an executable that is using the Portable Executable file format. A number of different sections exist in this kind of file, the most important one being the .text section, which contains the actual machine code for the program.
This machine code is what we get when we assemble our own assembly instructions; it’s the binary data that’s able to actually control what our CPUs are doing, as it speaks in the language of the machine.
In regards to a game’s executable, this machine code is most likely going to originate from the compiler responsible for compiling the human-written code for the game. Since most games are coded using C++, it follows that the machine code for most games is coming from a C++ compiler.
Decisions such as where a particular piece of code goes in regards to a class or file in the project hierarchy are human decisions. Decisions such as where a C++ class ends up in regards to its representative machine code in the program’s entire blob of executable code are compiler decisions. They are going to be made with performance being the main consideration, and will in no way reflect at all where that code might have existed in a more human-friendly development environment.
If a patch is adding a new feature, like, let’s say, a new map or level, this new code is most likely not going end up being appended to the rest of the game’s machine code. It’s much more likely to be inserted somewhere within it, its exact location a compiler matter, with the particular criteria perhaps being something along the lines of how much other code is referencing it, etc.
New code cannot exist in a vacuum; it will more than likely need to be referenced and executed by existing game code for it to have any sort of effect. That means changes are going to be made somewhere within that existing blob of machine code as well.
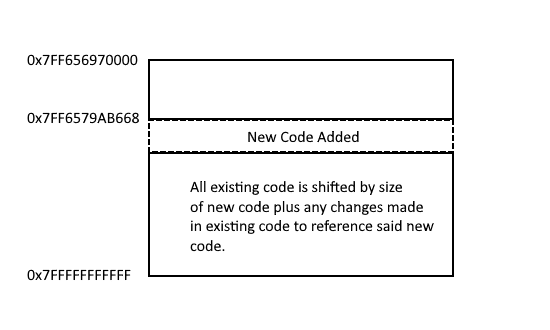
All of that being said, any kind of change resulting in additional (or less, I suppose) instructions being present into a particular place in the game’s machine code will result in all instructions that follow it to shift in location based on the number of new instructions inserted. Given how adding new code results in shifts both after said new code and after any referencing code, there is an incredibly high chance that the code our hacks might be targeting will no longer be where they used to be following an update to the executable file.
Again, this isn’t the sole reason a patch might break one of our hacks, but it is the most common reason. Before we go into all those other reasons, let’s start to talk about how we can go about fixing our hacks broken due to a patch changing the location of targeted assembly instructions.
How To Fix Hacks Broken by Instruction Movement
Let’s now figure out how we can go about fixing our hacks after a patch has occurred. This section will only apply if you’re using the (much higher performing) injection method where the exact address (using an offset) of the instruction to replace is used. If you inject your code using the unique array of bytes technique, then hopefully your code didn’t break.
If you were using the unique array of bytes technique and it did break, you might be in a bit of trouble, and therefore I would refer you to this particular section where I go over how to deal with this specific scenario. I’d then recommend to read the next section after that if that doesn’t work out for you.
Most low-quality hacks out there, such as cheats for a game (which I do not write, I make games harder and Omnified) use the unique array of bytes injection exclusively, so if you’re reading this because you’re trying to fix someone else’s hack, you probably fall into this camp.
Otherwise, assuming your collection of injections make use of exact addresses, how do we fix the hacks that aren’t working anymore? Simple! The first step is to get ready the unique array of bytes sequence we wrote down just in case a patch happened to come out in the future that would break our code.
Wait, you don’t have a relevant unique array of bytes written down? Oops. This is that bit of “discipline” I was referring to earlier. Always write down a high-quality unique array of bytes you can use to relocate your hacks, even if you aren’t using an array of bytes to actually perform the injection.
What makes a unique array of bytes high quality? We’ll explore this question in the next section, where I’ll go over patch changes that will result in your typical unique array of bytes fail — a high-quality unique array of bytes is one that survives all of those kinds of changes, and will be made clear as to its exact nature later on.
How do we get a unique array of bytes? Well, you can start off simply by opening an Auto assemble window and performing an AOB Injection into the same place of code in much the same way as was demonstrated here. This will give you a unique array of bytes you can copy over into your own code, however it will not necessarily be high quality (again, we’ll go into what else to look for in the next section).
Now, back to fixing patch breakage: once you have your unique array of bytes copied into your clipboard (assuming you aren’t a masochist who wants to manually type it all out), head on over to your Cheat Engine search interface. We’re going to search for the code, and the first thing we want to do is change the Value Type to Array of byte.
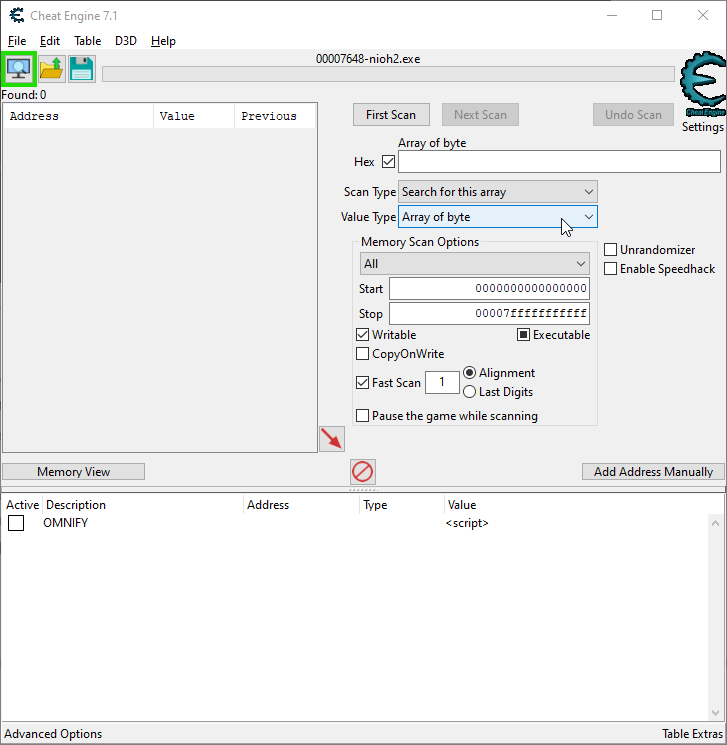
By default, all searches using Cheat Engine only include memory that is writable. This makes sense, as we are typically looking for values that are changing during gameplay, such as health and location. To change this behavior, right click nearby where it says Writable, and choose Preset: Scan writable memory.
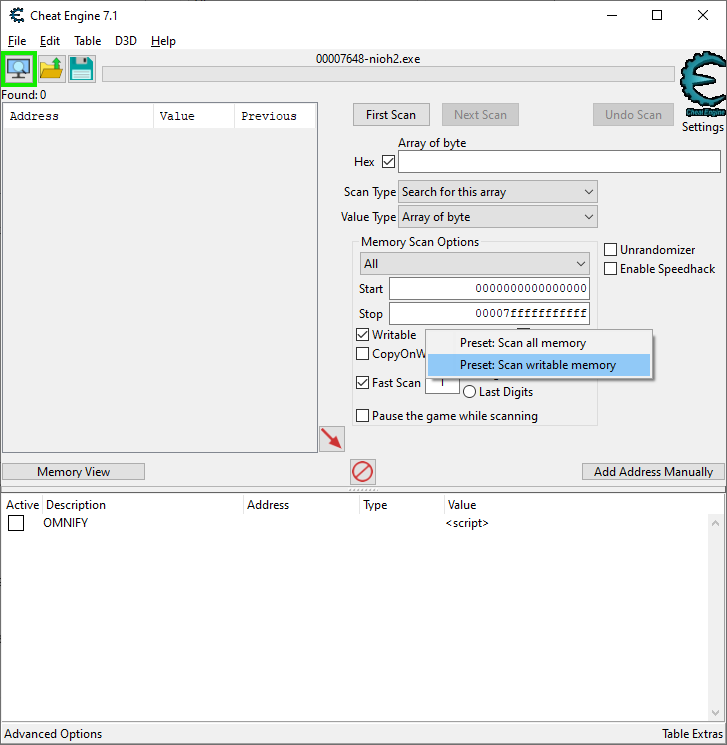
After this, paste in our unique array of bytes to the search field, hit the First Scan button, and cross your fingers. If all goes well, you’ll get a single result in the search results.
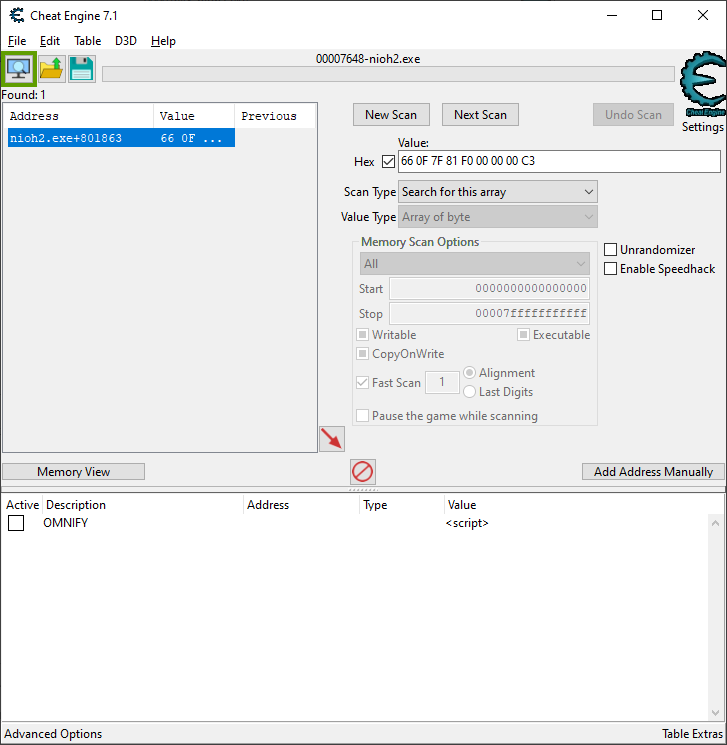
As we can see in the above image, our target instruction has been located, with the offset of 0x801863 being displayed. We simply take that offset and replace what we had in our code, and we should be good. At the time of writing, this particular hack was already updated to work with the latest version of Nioh 2, so the offset shown above is the same as it is in the previous snapshotted source code snippet (just in case you noticed).
What To Do if a Unique AOB Fails
Forgot to write down a unique array of bytes, or did and failed to get any results? Then one of the following is most likely true:
- the unique array of bytes was low quality, and couldn’t survive a particular type of change from the patch (the most likely reason),
- the instruction being targeted was changed as a result of an actual change in gameplay mechanics made by a human developer, and not due to a compiler decision (very rare and something I’ve never seen; assembly instructions live in a world apart from code us humans typically write), or
- the actual instruction has been removed due to stripped functionality or from a giant refactoring of code (again possible, but something I’ve simply never seen occur before in a shipped game’s codebase, though of course, I’m not omniscient).
At this stage, we’re basically in damage control mode. If it’s the case that you don’t have a unique array of bytes recorded, you can try to search for the instruction (using the method shown in the previous section) using the array of bytes we’re actually replacing (this is the array of bytes being checked in the assert statement), and see what you get.
More than likely, you are probably going to get a lot of results. If it is a manageable amount, at least you have something you can work with; you should be able to figure out which one is the correct one with some debugging, assuming you’ve previously worked with the code, or have some kind of idea as to what sort of data is passed through it and when it is called.
If you do have a unique array of bytes, and it’s turning out to be no good, start to chip off leading and trailing bytes or replace them with asterisks (not entirely sure if you can substitute a single nibble with an asterisk, or are only allowed to substitute an entire byte’s worth of data). This may lead to results that are hopefully not within the hundreds, as that’s a bit too many to have to sift through.
If you still get nothing, even when trimming it down so small that you’re only searching for the instructions you were originally trying to replace, then that means that particular instruction indeed no longer exists within the target binary. This is most likely due to a compiler decision, and something that is actually preventable ahead of time if you know what to look for.
At this point, you’re going to have to reverse engineer the injection site again. You’re on your own there, however feel free to refer to my many articles on Omnifying in order to see how I reverse a large number of different things in games.
Next, we’ll take a look at how the make the most “patch-proof” code possible, by discussing patch changes that will wreck most unique arrays of bytes, and how we can secure a high-quality unique array of bytes to protect us from these changes.
Preventing Breaks That Change Unique AOBs
As I’ve already established, assembly instruction injection using specific memory addresses will most likely break following an update to the binary due to the shifting of the instructions within it. A unique array of bytes gives us something that allows us to find the code without having to reverse engineer everything again.
If we’re not careful however, and end up with a low-quality unique array of bytes, we may find that we’re unable to locate our targeted instructions following a patch, due to our unique array of bytes not surviving the change. I’ll be going over various real-life examples of code where this can occur, hopefully demonstrating to you how you can craft your own high-quality unique arrays of bytes in your own hacking travels.
Don’t Target Instructions That Include Static Addresses
For our first example of code for which a unique array of bytes will be rendered useless following a patch, we’re going to take a look at some of my Omnified Nioh 2 code, in particular some code where I’m hooking into the options of the game (configurable via in-game menus).
Here’s the exact place we’re hooking into, which I was led to through a bunch of reverse engineering that pointed us to it. This is how it appears prior to us injecting any code into it:
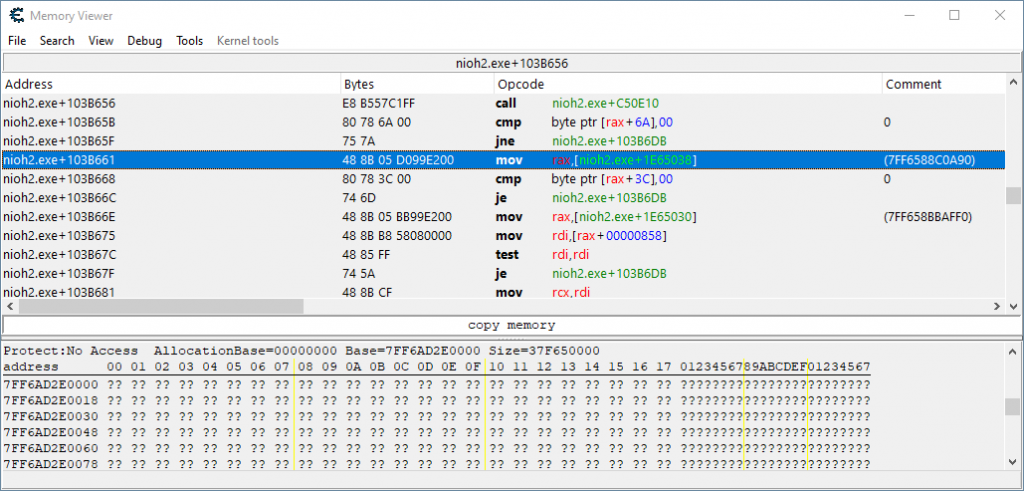
Alarm bells immediately start ringing in my head just from looking at this injection target. You’ll see why when we attempt to get a unique array of bytes for this particular place in code. To do so, we open up an Auto assemble window, and choose Template -> AOB Injection.
After doing so, we’re going to get the following template code (only including the relevant bits):
aobscanmodule(INJECT,nioh2.exe,48 8B 05 D0 99 E2 00) // should be unique alloc(newmem,$1000,"nioh2.exe"+103B661) label(code) label(return) newmem: code: mov rax,[nioh2.exe+1E65038] jmp return INJECT: jmp newmem nop 2 return: registersymbol(INJECT)
There are a few problems with this injection. The first problem is the instruction we see underneath the code label, a label which I always will name as nameOfHookOriginalCode in my own code, as that’s what it is: the original game code we’re replacing. The other problem has to do with that unique array of bytes Cheat Engine generated for us at the top.
The original instruction being replaced, mov rax,[nioh2.exe+1E65038], is a simple read memory instruction. Nothing fancy. But what’re we reading from? We’re reading some data found in another part of the binary. A static place in the binary. Ring any bells?
Yes, like our own targeted instructions whose locations are destined to change following an update, so too will the place the above code will probably want to read its desired data from.
Even if the location of this particular piece of code does not change (as in, we do not have to update the offset applied to nioh2.exe which we’re injecting into), then there’s a high chance it will still fail due to the assert statement or that we will get a crash, as there is a very high chance that the patched binary will need to be reading from a different address than the one we see above.
This leads to one of the many maxims I follow when constructing a good hook:
Don’t hook into places that require us to replace original code which is referencing a static address.
But what I just described is not the biggest problem; the biggest problem lies with the generated unique array of bytes itself, which, if you look above, is reported as 48 8B 05 D0 99 E2 00 by Cheat Engine. What’s the problem with this?
Well, Cheat Engine isn’t lying to us: it is indeed unique. However, what does it translate into?
mov rax,[nioh2.exe+1E65038]
Oops. The unique array of bytes includes (and it would, of course) that problematic part of the instruction we just talked about. The address in static memory which is highly likely to change following a patch. And, it follows, if a part of an instruction that’s part of a unique array of bytes changes, so too will the unique array of bytes for locating it. At least, most of the time.
The unique array of bytes for this code probably won’t survive a patch.
So, what do we do?
Ideally, we hook into somewhere nearby, where the data we need is still available, but does not require us to replace instructions that contain any static addresses that are likely to change. This is not always that easy or even possible, and the very code we’re looking at here is no exception.
This particular code is only executed under an even more particular set of conditions. We’re unable to go a single instruction above the one we originally wanted without losing that guarantee that we’re looking at the appropriate data. We are, however, still within an appropriate execution context if we hook into a single instruction below. So, let’s take a look at that.
If you look at the previous image, you’ll see that the instruction below our original one, cmp byte ptr [rax+3C],00, looks a lot safer than the one we were just trying to hook into. Let’s see what a hook and its unique array of bytes looks like for this code using the same method as described before.
aobscanmodule(INJECT,nioh2.exe,80 78 3C 00 74 6D) // should be unique alloc(newmem,$1000,"nioh2.exe"+103B668) label(code) label(return) newmem: code: cmp byte ptr [rax+3C],00 je nioh2.exe+103B6DB jmp return INJECT: jmp newmem nop return: registersymbol(INJECT)
Ah crap. Unfortunately for us, injecting into this code requires us to have to replace not only the instruction below our original one, but also the instruction that follows it. And, unfortunately, that second instruction also appears to be referencing a static address in memory.
So, following a patch, the address being jumped to, as it is defined under the above code, is absolutely almost guaranteed to change.
But let’s take another, quick look here. Where exactly is this instruction jumping to? From the code, we can see that, if conditions are such that a jump will occur, we’ll be traveling to nioh2.exe+103B6DB from nioh2.exe+103B66C. This is actually a rather short distance to travel, and we can see this reflected in the actual machine code that gets generated from this instruction: 74 6D.
By looking at this sequence of bytes, we are now operating within the realm of machine code opcodes and their arguments, something even more complicated than assembly, and something I certainly must increase my own knowledge on. There’s never a bad time to expand our knowledge on anything, however, so let’s take a look at this particular machine code and see what it all means.
0x74 represents the opcode for the je (jump if equal) instruction. That’s very simple. The argument, 0x6D is clearly not a gigantic address to somewhere in static memory, but instead an offset. Indeed, the distance between the instruction after nioh2.exe+103B66C and nioh2.exe+103B6DB is 0x6D.
This leads to a second maxim that expands upon the first:
Small offsets are less likely to change, and therefore safe to use as a unique array of bytes, whereas large offsets are not safe.
Even though the effective address is most likely destined to change following a patch, the machine code produced from the instruction, which is part of the unique array of bytes we’d use to locate said instruction, will most likely not. This means that a unique array of bytes produced from this instruction would be a fairly high-quality one relatively safe to use.
I say “a fairly high-quality one” because even though an “offset” of 0x6D is much smaller than the gargantuan difference in addresses exhibited by the original mov instruction, it’s not as small as I’d like in order for my paranoia to be completely alleviated. It will only break if there are instructions inserted into or removed from the 0x6D range of instructions being jumped.
Have I seen changes happen within such a limited range of a program’s code? Yes, especially in an oft adjusted area such as the code that reads from a game’s user options. However, it is relatively rare. Therefore, I can say that we are probably OK in using this unique array of bytes. If finding this particular code required hours upon hours of reverse engineering, I’d take some extra steps and find nearby code made up of a purely unique combination of instructions that lack any distant memory accesses instead.
Also, even though we’ve determined that this new unique array of bytes is safe, we’re unfortunately still technically violating the first maxim I shared here, in that I prefer not to have hooks that have to replace any code referencing static memory. This is mainly a quality concern, not a data safety one.
We have little choice in this case however, due to the limited wiggle room I described earlier. We must hook in here. Therefore, I would just swallow my pride and use this as a hook, and know that I would need to remember to update the effective static address being reference under the nameOfHookOriginalCode label of the hook. Know, however, that I avoid this practice whenever possible.
All of this talk of the dangers of distant static memory being referenced in our chosen unique array of bytes brings us to another, somewhat related, yet distinctly different potential breaking point in our hacks, and that has to do with deep data structures.
Don’t Target Instructions That Include Deep Data Structures
We’ll now be taking a look at the type of change from a patch which I attribute as being responsible for the most unexpected breaks to my prepared unique arrays of bytes. The majority of code we hook into should be both primitive and essential, making the code very unlikely to change following an update. While we can rest assured with most of the things we hook into, we can often be caught off-guard by the seemingly innocuous presence of reads from dynamic memory that has some depth to it.
Like the previous instruction, it’s best that we start off with a real-life example. For this example, we’ll be taking a look at a hook I made for reading the player’s ammunition count for Omnified Cyberpunk 2077:
// Gets the player's magazine prior to a gun firing.
// UNIQUE AOB: 0F B7 8E 50 03 00 00
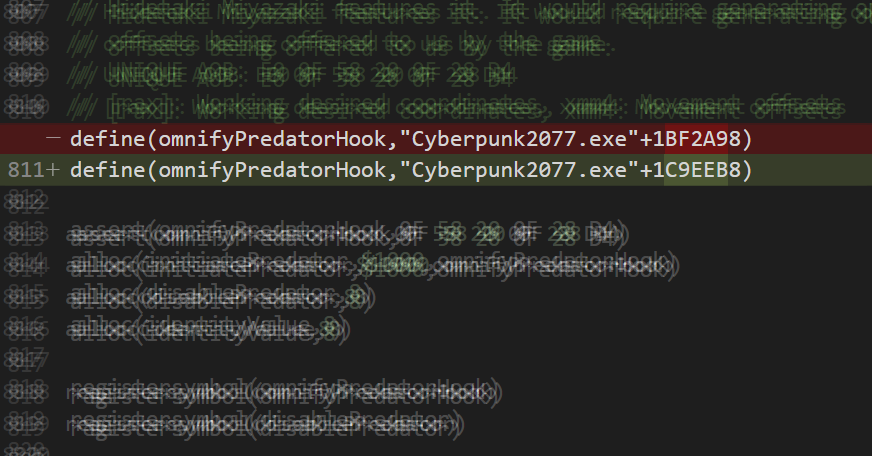
define(omniPlayerMagazineBeforeFireHook,"Cyberpunk2077.exe"+1B95E93)
assert(omniPlayerMagazineBeforeFireHook,0F B7 8E 50 03 00 00)
alloc(getPlayerMagazine,$1000,omniPlayerMagazineBeforeFireHook)
alloc(playerMagazine,8)
registersymbol(omniPlayerMagazineBeforeFireHook)
registersymbol(playerMagazine)
getPlayerMagazine:
pushf
cmp r12,0
jne getPlayerMagazineOriginalCode
cmp r13,0
jne getPlayerMagazineOriginalCode
push rax
mov rax,playerMagazine
mov [rax],rsi
pop rax
getPlayerMagazineOriginalCode:
popf
movzx ecx,word ptr [rsi+00000350]
jmp getPlayerMagazineReturn
omniPlayerMagazineBeforeFireHook:
jmp getPlayerMagazine
nop 2
getPlayerMagazineReturn:
For the purposes of this article, we want to mainly focus on the original game code that can be found under the getPlayerMagazineOriginalCode label. What the original code is doing here is reading the number of bullets the player has remaining in their current gun’s magazine.
The rsi register is pointing to a data structure associated with the gun that the player currently has equipped. Deep within this data structure, specifically at [rsi+0x350], we can find the number of bullets left in the gun’s magazine or “clip” (a term that I know gun enthusiasts hate, haha).
The sole original game instruction, movzx ecx,word ptr [rsi+00000350], is assembled into the machine code 0F B7 8E 50 03 00 00, which indeed acts as unique array of bytes used to locate this particular injection site. The question we should be asking ourselves now is: will this array of bytes survive a patch?
Spoiler: it did not. At least, not the patch that brought the version of the game to 1.3, released during my Omnified playthrough. Let’s take a minute to examine why that’s the case by first looking at another example that actually did survive that patch.
We often rely on the reads to various character values themselves to act as the unique arrays of bytes meant to relocate said reads in the future. Here’s such an example, in a hook I have for Omnified Nioh 2, injected into code that is reading the player character’s current health amount:
// Creates pointers to multiple structures containing important player data.
// Filtering is achieved by looking at the root containing structure pointed
// at by rax.
// If it is the player, the base of this structure will be set to 0x64.
// We adjust the health structure's address by +0x10 bytes here as the game,
// while accessing current health values using an 0x20 offset, will write to
// it using a 0x10 offset.
// [rcx+20] | {[player]+10}: Current health.
// [rcx+18] | {[player]+8}: Maximum health.
// [rcx+48] | {[player]+38}: Current stamina.
// [rcx+4C] | {[player]+3C}: Maximum stamina.
// [rcx+B8] | {[player]+A8}: Location structure.
// [rcx+14C] | {[player]+13C}: Identifier for entity type.
// UNIQUE AOB: 41 8B C6 48 3B 41 20
define(omniPlayerHook,"nioh2.exe"+807269)
assert(omniPlayerHook,41 8B C6 48 3B 41 20)
alloc(getPlayer,$1000,omniPlayerHook)
alloc(player,8)
alloc(playerLocation,8)
alloc(recallYCorrection,8)
registersymbol(recallYCorrection)
registersymbol(playerLocation)
registersymbol(player)
registersymbol(omniPlayerHook)
getPlayer:
pushf
cmp [rax],64
jne getPlayerOriginalCode
sub rsp,10
movdqu [rsp],xmm0
push rax
push rbx
// Adjust the base address of our root structure so it is aligned with how it is when
// being processed by various functions of significance (damage application code, etc).
mov rax,rcx
add rax,0x10
mov [player],rax
// Grab the player's location structure, and apply any pending Recall action to it.
mov rax,[rcx+B8]
mov [playerLocation],rax
mov rbx,teleport
cmp [rbx],1
jne getPlayerCleanup
mov [rbx],0
mov rbx,teleportX
movss xmm0,[rbx]
movss [rax+F0],xmm0
movss [rax+220],xmm0
mov rbx,teleportY
movss xmm0,[rbx]
// The game sometimes needs a bit of a vertical boost to avoid us from sinking in
// the ground when we're teleporting somewhere arbitrary.
addss xmm0,[recallYCorrection]
movss [rax+F4],xmm0
movss [rax+224],xmm0
mov rbx,teleportZ
movss xmm0,[rbx]
movss [rax+F8],xmm0
movss [rax+228],xmm0
getPlayerCleanup:
pop rbx
pop rax
movdqu xmm0,[rsp]
add rsp,10
getPlayerOriginalCode:
popf
mov eax,r14d
cmp rax,[rcx+20]
jmp getPlayerReturn
omniPlayerHook:
jmp getPlayer
nop 2
getPlayerReturn:
recallYCorrection:
dd (float)150.0
Again, the important part for our purposes here is the original code found underneath the getPlayerOriginalCode label. The second instruction in this original code, cmp rax,[rcx+20], is not so different from our previous example. It is making an access to some character data, this time the player’s health, by reading from [rcx+0x20].
The biggest difference between this code, which is again accessing the player’s health, and the previous code, which is accessing the player’s magazine, has to do with the depth of the particular data access. The access to the player’s health, located at [rcx+20], is much closer to the base of the structure, and indicates to us that the health is perhaps the primary data point inside the structure.
Let’s compare that to the access being made to the player’s magazine count, located at [rsi+0x350]. This is a much deeper access into a data structure for a particular type of desired data, and if nothing else, it seems to indicate that there may be other weapon-related pieces of data situated along the way to the magazine count.
As I indicated previously, the unique array of bytes originating from the read to the player’s ammunition did not survive a patch to Cyberpunk 2077, and that’s because the patch saw actual changes to the data within these particular weapon-related structures.
To best demonstrate how, this is what the instruction actually looked like prior to the patch:
movzx ecx,word ptr [rsi+00000340] (0F B7 8E 40 03 00 00)
And, here it is, once again, after the patch:
movzx ecx,word ptr [rsi+00000350] (0F B7 8E 50 03 00 00)
Clearly, the patch added some new type of feature, one I don’t remember being called out in the patch notes (meaning it is most likely something for internal use only), to the weapon data structure we were using in order to get the ammo count. This new, unwanted data wasn’t even appended to the structure, but rather wedged somewhere inside of it, pushing the data we were looking for deeper into the structure, to the tune of 0x10 bytes.
All of this hearkens back to the second maxim I wrote in the previous section, in that small offsets are safe, but large offsets are not. This maxim holds up whether we’re talking about offsets being applied to the instruction pointer (in regards to jmp instructions) or offsets being used to access a type of value within a data structure.
The risk is even greater when we’re talking about data structures that hold a number of different value types, therefore, let’s add one more maxim to the mix:
Primary value types of a data structure are safe, random non-primary data points within a structure are not.
Another example of this, also in Cyberpunk 2077, can be found by looking at how the data structure that held all of the characters “stats” (experience, level, street cred, other character sheet statistics) changed. Prior to a patch, the experience points for the character could be found at:
mov [rsi+60],bl (88 5E 60 48 85 C9)
And after the patch, this was unfortunately changed to:
mov [rsi+63],bl (88 5E 63 48 85 C9)
Clearly, the patch appeared to add another statistic to player characters, once again wedging it in the middle of all things and not at the end. This isn’t even that deep of an access, with the offset only being 0x60. It is yet another prime example of why it is important to avoid relying on non-primary data points within busy data structures as our means to locate said pieces of code in the future after a patch.
Taking that under consideration, we can say that if we have to use a data structure access as part of a unique array of bytes, we should make sure the access is being made for that data structure’s primary value type. Of course, what is and isn’t a data structure’s primary value type is something we must determine ourselves; however, with some experience, I believe this is not the most difficult kind of determination (or “reverse engineering guess”, if you will) to make correctly.
Think of source-of-truth location coordinate data structures in most games: the offset used to read and write from and to these will more often than not be the same throughout the application (plus or minus a few bytes, as I’ve seen data structures aligned at different base points for writes vs reads in a number of games). It isn’t going too far out on a limb to say, for these particular location coordinate data structures, that the source-of-truth coordinates (found starting at, let’s say, 0xF0, as they do in Nioh 2) are the primary value types for said structures.
I’ve never seen the location of a primary value data point within a critical game data structure shift from a patch during any of my hacking, so this is something I bank on, and most likely something you can bank on too.
Unique Combinations of Easy Instructions Are Key
Hopefully this article has made it clear that no assembly-injected hack into a binary that’s still in service by the developer is truly safe from being affected by updates. Recorded unique arrays of bytes help us relocate the particular code we’re interested in, and can be the main mode of injection itself if we so choose, but such arrays require careful consideration and selection, lest they too be lost due to changes forced upon us.
If a particular piece of code took a significant amount of effort in order to find, it makes sense to take a little time and make sure that whatever code you end up using to be able to locate the injection site in the future be as resilient to change as possible. It is amazing how, given that there are thousands upon thousands of instructions in these binaries, that one can find, with relative ease, groups of instructions that are unique in their sequence and form.
So, bear in mind the dangerous types of code I’ve pointed out, and if all else fails, find a nice glob of simple looking instructions nearby your injection sites; ideally, instructions that are neither accessing static memory nor performing any deep reads of non-primary value types from data structures. After that, simply make a note of their unique array of bytes as well as their distance from the injection site, writing all of this down for future reference.
With this much caution, you can’t go wrong. Hope you learned something that will help you make your own binary experiments more resilient, lessening the pain of any patches that come your way in the future.
Thanks for your time and interest! Until next time.