An integral part of the MonoGame development experience is the packaging and loading of content via MonoGame’s content pipeline. This is the mechanism used by MonoGame to process game-related data and then load it in a platform-neutral manner at runtime.
The MonoGame content pipeline is equipped with the ability to handle many common game-related data types; however, even early on in my quest to learn how to develop my own game, I wanted to add support for sending custom types of game content of my own through the pipeline.
Fortunately, we can do just that by authoring an extension to the content pipeline. Unfortunately, I had trouble finding any sort of modern and comprehensive guide on how to do this. So, this seemed like a good topic for me to share regarding my experiences with it.
This article will provide an overview of the content pipeline extension process, going over all of the many different components required. I’ll then spend some time detailing each part, sharing (what I consider to be) “best practices” for what to do.
Extending the Pipeline: A General Overview
A content pipeline extension library is a .NET assembly that’s referenced within a .mgcb file and then invoked by the MonoGame Content Builder, with the result being custom data getting encoded and stored in MonoGame’s XNB format.
We can reference a pipeline extension library through the MGCB editor:
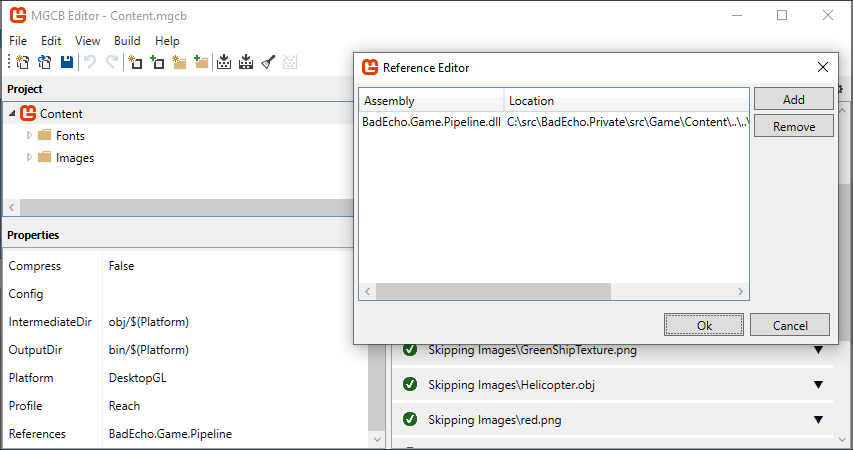
Alternatively, we can add a /reference switch to the .mgcb file directly:
#-------------------------------- References --------------------------------#
/reference:path\to\Extension.dllThe pipeline extension library itself is only the first of the two major actors here: a consuming reader of the encoded data is also required. This will exist, most likely, within some kind of central framework to the game, or the game itself.
So, we have a producer of encoded game data and a consumer. With that in mind, let’s take a look at what a very high-level overview of the whole process looks like.
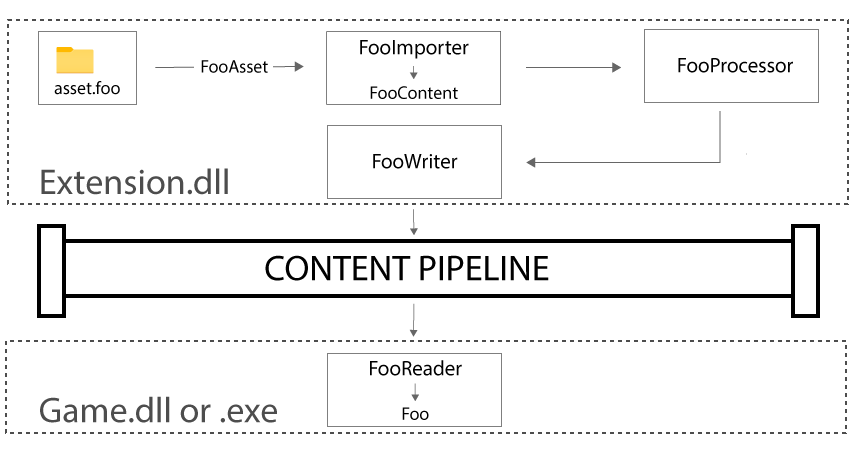
This, more or less, illustrates all of the various pieces in play when we talk about a pipeline extension. More specifically, we have
- a raw game asset, serialized into a DTO-styled
FooAssetobject type; - a content importer (
FooImporter) that loads an instance of asset data and converts it into aFooContentcontent item; - a content processor (
FooProcessor) that takes a provided content item and further validates and processes it; - a content writer (
FooWriter), responsible for actually writing the data to the content pipeline; and - a content reader (
FooReader) which reads the data from the content pipeline and constructs an instance of a model class for the data (Foo).
We start with a FooAsset data object and end up with an instance of the Foo type, which is part of our game’s domain model. That is, it is a representation of the game asset equipped with behaviors and functionality, such as the ability to draw itself.
With our general overview complete, let’s take a more detailed look at how to author a pipeline extension.
Pipeline Extension Project
For the rest of this article, we’re going to be authoring a pipeline extension that adds support for sprite sheets. So let’s get to it.
To create a new pipeline extension, we can make use of a template that comes with MonoGame’s C# project templates extension.

Using this template will create the following:
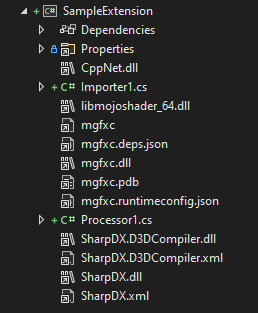
The various .dll, .pdb, and other kinds of “junk” files we see here are not being directly added to the project by the pipeline extension template; instead, they are byproducts of said template’s automatic referencing of the MonoGame.Framework.Content.Pipeline NuGet package.
It’s a NuGet thang.
I’m not exactly a fan of having all this garbage displayed in my code projects; luckily, we can clean up the view in Solution Explorer by editing the pipeline extension’s .csproj file.
Add to Project File to Hide Pipeline Garbage
<ItemGroup> <Content Remove="\**\*\CppNet.dll" /> <Content Remove="\**\*\libmojoshader_64.dll" /> <Content Remove="\**\*\mgfxc*" /> <Content Remove="\**\*\SharpDX.*" /> </ItemGroup>
This cleans up the view of the project in Solution Explorer, and I’ve observed no adverse effects from doing this (everything compiles and runs fine).
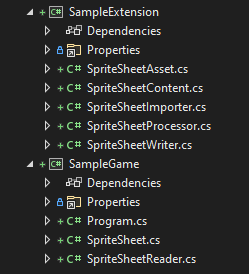
After that, let’s rename the stock classes and add a few more requisite types to our pipeline extension project:
SpriteSheetAsset.csSpriteSheetContent.csSpriteSheetImporter.cs(renamedImporter1.cs)SpriteSheetProcessor.cs(renamedProcessor1.cs)SpriteSheetWriter.cs
We then need to add a few types to our consuming game or game framework project:
SpriteSheetReader.csSpriteSheet.cs
In the end we’ll have something looking like this:
Let’s go into detail for each of these components, and what we need to do to add sprite sheet support to the content pipeline.
The Asset
The asset is the file containing game data being imported as content into the pipeline. The goal of the content pipeline is to take game-related assets and encode them so they can be packaged with our game and then loaded and made use of in our game during runtime.
Assets come in all shapes and sizes: for 3D models, the assets may come in (but not only in) the form of .obj, whereas assets for 2D textures might take the shape of .png files.
Inside our pipeline extension, the very first thing we do usually involves the loading of this data into a DTO-styled object type that is strictly for deserialization, which in our case will be the SpriteSheetAsset class.
What a Sprite Sheet Asset Looks Like
Our sprite sheet assets consist of two components:
- A
.spritesheetfile containing metadata that directs the sprite sheet’s runtime behavior. - The image of the sprite sheet itself, specified in the
.spritesheetconfiguration and contained in a 2D texture file (.png,.jpg, etc.).
A sprite sheet texture’s source image contains every frame of animation for the sprite. The game engine needs additional information, however, such as the number of frames as well as when said frames should be drawn.
The root document for a sprite sheet, the .spritesheet file, provides this information.
What SpriteSheetAsset Looks Like
The .spritesheet file is simple JSON data, therefore our SpriteSheetAsset type is a simple data type suitable for deserializing said JSON data into.
That means a very barebones DTO-styled class containing mainly properties with simple getters and init only setters. Let’s use what I have in the Bad Echo Content Pipeline Extension’s sprite sheet code as an example.
SpriteSheetAsset.cs
/// <summary>
/// Provides configuration data for a sprite sheet asset.
/// </summary>
public sealed class SpriteSheetAsset
{
/// <summary>
/// Gets or sets the path to the file containing the texture of the individual animation
/// frames that compose the sprite sheet.
/// </summary>
public string TexturePath
{ get; set; } = string.Empty;
/// <summary>
/// Gets the number of rows of frames in the sprite sheet.
/// </summary>
public int Rows
{ get; init; }
/// <summary>
/// Gets the number of columns of frames in the sprite sheet.
/// </summary>
public int Columns
{ get; init; }
/// <summary>
/// Gets the row for upward movement.
/// </summary>
public int RowUp
{ get; init; }
/// <summary>
/// Gets the row for downward movement.
/// </summary>
public int RowDown
{ get; init; }
/// <summary>
/// Gets the row for leftward movement.
/// </summary>
public int RowLeft
{ get; init; }
/// <summary>
/// Gets the row for rightward movement.
/// </summary>
public int RowRight
{ get; init; }
/// <summary>
/// Gets or sets the row containing initially drawn frames, prior to any movement occurring.
/// </summary>
public int RowInitial
{ get; set; }
}
Very simple stuff that will easily serve as an output type for any JSON deserializer, which is exactly how our importer will be creating instances of our asset type.
Note that the texture path is mutable; all external paths to other assets need to be mutable so paths may be normalized in relation to the working directory of the MGCB (which will most likely be a level or two removed from where the sprite sheet and any external asset lives).
The Content
Our notion of an “asset” doesn’t actually exist in MonoGame’s world. The MonoGame Content Pipeline only deals with just that: content.
Our imported sprite sheet data must be recognized as content, or more specifically: as a subclass of Microsoft.Xna.Framework.Content.Pipeline.ContentItem.
That’s…basically it. It just needs to derive from ContentItem. Since we find ourselves in a situation of forced subclassing, I make use of a base type that simply exposes a provided asset type while offering some additional, very commonly needed functionality.
ContentItem.cs
/// <summary>
/// Provides typed raw data for a game asset.
/// </summary>
/// <typeparam name="T">The type of asset data described by the content.</typeparam>
public abstract class ContentItem<T> : ContentItem, IContentItem
{
private readonly Dictionary<string, ContentItem> _references = new();
/// <summary>
/// Initializes a new instance of the <see cref="ContentItem{T}"/> class.
/// </summary>
/// <param name="asset">The configuration data for the game asset.</param>
protected ContentItem(T asset)
=> Asset = asset;
/// <summary>
/// Gets the configuration data for the game asset.
/// </summary>
public T Asset
{ get; }
/// <inheritdoc/>
public void AddReference<TContent>(ContentProcessorContext context,
string filename,
OpaqueDataDictionary processorParameters)
{
Require.NotNull(context, nameof(context));
var sourceAsset = new ExternalReference<TContent>(filename);
var reference =
context.BuildAsset<TContent, TContent>(sourceAsset,
string.Empty,
processorParameters,
string.Empty,
string.Empty);
_references.Add(filename, reference);
}
/// <inheritdoc/>
public ExternalReference<TContent> GetReference<TContent>(string filename)
{
if (!_references.TryGetValue(filename, out ContentItem? contentItem))
{
throw new ArgumentException(Strings.NoReferenceInContentItem.InvariantFormat(filename),
nameof(filename));
}
return (ExternalReference<TContent>) contentItem;
}
}
The IContentItem interface exists to allow for easy swapping of reference sources between various types of content writers, something that becomes required when dealing with assets that may either exist in standalone external assets or embedded in some type of host asset.
As for what purpose the AddReference / GetReference methods serve: we’ll get into that during the importing and processing stages.
What SpriteSheetContent Looks Like
Well, that’s pretty simple.
SpriteSheetContent.cs
/// <summary>
/// Provides the raw data for a sprite sheet asset.
/// </summary>
public sealed class SpriteSheetContent : ContentItem<SpriteSheetAsset>
{
/// <summary>
/// Initializes a new instance of the <see cref="SpriteSheetContent"/> class.
/// </summary>
/// <param name="asset">The configuration data for the sprite sheet.</param>
public SpriteSheetContent(SpriteSheetAsset asset)
: base(asset)
{ }
}
You could remove the abstract modifier from ContentItem<T> and simply use ContentItem<YourAsset>, but it starts to get a bit messy with nested generics later on.
The Importer
The content importer has three main responsibilities, namely
- loading the asset data from disk,
- marking external file dependencies, and
- performing file I/O specific validation and processing.
Loading the Asset Data From Disk
The content importer is the one component that is provided with the file path to the asset that we need to load.
If we designed our asset classes correctly, then loading them from disk will hopefully be as simple as taking the provided path and feeding it to our deserializer of choice.
Marking External Dependencies
For asset types like our sprite sheets, two files are involved: the .spritesheet file and the texture image file. A content importer is only associated with a single “kind” of file extension, however (i.e., image types, or some kind of plain text format).
This is good because that means (in the case of our sprite sheet assets) we only need to bother with adding a single .spritesheet entry to our .mgcb file; we don’t need to worry about adding an entry for the texture file as well.
While that’s great, we need to register these external assets as dependencies so that our asset data gets reimported if any changes are committed to said dependencies (i.e., .spritesheet hasn’t been touched, but the texture has been updated).
The content importer is where we do this, and we do it by calling AddDependency(dependencyPath) on the ContentImporterContext that’s provided to the importer’s main function.
File I/O Specific Validation and Processing
The content importer is the only component cognizant of the file system. We normally leave the processing and validation of data to the content processor; however, anything related to file pathing is best handled by the importer as the processor is meant to be ignorant of all that and only concerned with the loaded data itself.
An example is the normalization of external asset paths. Very often, the external asset will be in the same directory as the core asset file; it would be entirely appropriate in this case that the texture path in the sprite sheet configuration simply reflect the name of the texture file.
However, the MGCB’s working directory will most likely be at the root of all the content it is building. It will fail to find this external asset whose path is relative to that of the file that specifies it. To remedy this, we’ll want to make sure we normalize the asset’s configured path to MGCB’s working directory.
What SpriteSheetImporter Looks Like
Let’s use some more code from the Bad Echo Content Pipeline Extension as an example.
SpriteSheetImporter.cs
/// <summary>
/// Provides an importer of sprite sheet asset data for the content pipeline.
/// </summary>
[ContentImporter(".spritesheet",
DisplayName = "Sprite Sheet Importer - Bad Echo",
DefaultProcessor = nameof(SpriteSheetProcessor))]
public sealed class SpriteSheetImporter : ContentImporter<SpriteSheetContent>
{
/// <inheritdoc/>
public override SpriteSheetContent Import(string filename, ContentImporterContext context)
{
Require.NotNull(filename, nameof(filename));
Require.NotNull(context, nameof(context));
context.Log(Strings.ImportingSpriteSheet.InvariantFormat(filename));
var fileContents = File.ReadAllText(filename);
var asset = JsonSerializer.Deserialize<SpriteSheetAsset?>(
fileContents, new JsonSerializerOptions { PropertyNameCaseInsensitive = true });
if (asset == null)
{
throw new ArgumentException(Strings.SheetIsNull.InvariantFormat(filename),
nameof(filename));
}
context.Log(Strings.ImportingDependency.InvariantFormat(asset.TexturePath));
asset.TexturePath
= Path.Combine(Path.GetDirectoryName(filename) ?? string.Empty, asset.TexturePath);
context.AddDependency(asset.TexturePath);
context.Log(Strings.ImportingFinished.InvariantFormat(filename));
return new SpriteSheetContent(asset) { Identity = new ContentIdentity(filename) };
}
}
We load the asset data from disk to its serialized type, we mark dependencies, and we normalize the texture path so that it contains any directory information our sprite sheet file name itself contains.
Some Other, Minor Notes
It’s good to make use of the logging capabilities exposed by ContentImporterContext so that we can provide some visibility into what our extension is doing during a build. The message will be visible in the standard output of MSBuild.
Another point of interest is the assigning of the content’s ContentIdentity. This isn’t something that’s strictly required by the content pipeline; however, it seems to be a practice followed by the stock content importers that ship with MonoGame.
It allows us to assign a friendly name to the asset and (more importantly) make a record of its source file path. This is the only way components that run later down the line (like the content processor) can be aware of anything related to the asset’s filesystem origins.
We’ve imported our data, time to send it through some processing.
The Processor
The content processor is where we should be doing the main chunk of validation and, for lack of a better term, “processing” of our asset data.
The processing required is going to be highly dependent on the data. Fancy kinds of data are going to have fancy kinds of processing! I’m looking at you Mr. 3D Fancy Model Graphics Processor!
We really don’t have to do much with our sprite sheet assets, however. We mainly just need to make sure that the sprite sheet configuration makes sense.
What About the Texture Though?
Oh yeah, if we have any external asset dependencies, the processor is where we need to hand off the…handling of said assets to the content pipeline.
We don’t want to get involved with any sort of manual importation and processing of built-in asset types ourselves. Rather, we want to package these external assets as ExternalReference<TContent> instances and then register them to be built by the content pipeline later down the line.
And that’s exactly what our ContentItem<T>.AddReference method (mentioned earlier) does! It’ll generate an ExternalReference<TContent> instance, and then initiate a nested build of the additional asset via ContextProcessorContext.BuildAsset<TInput,TOutput> method.
What SpriteSheetProcessor Looks Like
Let’s take yet another page from our Bad Echo Pipeline Extension code to see what our processor might look like.
SpriteSheetProcessor.cs
/// <summary>
/// Provides a processor of sprite sheet asset data for the content pipeline.
/// </summary>
[ContentProcessor(DisplayName = "Sprite Sheet Processor - Bad Echo")]
public sealed class SpriteSheetProcessor : ContentProcessor<SpriteSheetContent, SpriteSheetContent>
{
/// <inheritdoc/>
public override SpriteSheetContent Process(
SpriteSheetContent input, ContentProcessorContext context)
{
Require.NotNull(input, nameof(dinput));
Require.NotNull(context, nameof(context));
context.Log(Strings.ProcessingSpriteSheet.InvariantFormat(input.Identity.SourceFilename));
ValidateAsset(input.Asset);
// If no valid configuration was provided for the initial frame's row, we have it
// default to the first row.
if (input.Asset.RowInitial <= 0)
input.Asset.RowInitial = 1;
input.AddReference<Texture2DContent>(context,
input.Asset.TexturePath,
new OpaqueDataDictionary());
context.Log(Strings.ProcessingFinished.InvariantFormat(input.Identity.SourceFilename));
return input;
}
private static void ValidateAsset(SpriteSheetAsset asset)
{
if (asset.Rows <= 0)
throw new InvalidOperationException(Strings.SheetHasNoRows);
if (asset.Columns <= 0)
throw new InvalidOperationException(Strings.SheetHasNoColumns);
if (asset.RowUp > asset.Rows)
throw new InvalidOperationException(Strings.SheetUpwardRowOutOfRange);
if (asset.RowDown > asset.Rows)
throw new InvalidOperationException(Strings.SheetDownwardRowOutOfRange);
if (asset.RowLeft > asset.Rows)
throw new InvalidOperationException(Strings.SheetLeftwardRowOutOfRange);
if (asset.RowRight > asset.Rows)
throw new InvalidOperationException(Strings.SheetRightwardRowOutOfRange);
if (asset.RowInitial > asset.Rows)
throw new InvalidOperationException(Strings.SheetInitialRowOutOfRange);
}
}
We validate, do a tiny bit of processing, and register all those external assets to be built by the pipeline independently from our extension.
Some Other, Minor Notes
Much like the content importer, it’s useful if we provide some kind of visibility during the build process thorugh logging. In the case of content processors, we can make use of the logging capabilities exposed by the provided ContentProcessContext instance to do just that.
Now that we have imported and processed our data, it’s time to stuff it into the pipeline!
The Writer
We’re getting close to the end! Well, as far as the pipeline extension library itself is concerned, I suppose.
The content writer is what takes our imported and processed content item and then writes it to the output stream that is packaging the data inside the .xnb content file.
This code looks a lot “lower level” than other code we’ve been dealing with; we’re literally taking our content data and writing all of its values into an output stream.
While we’re doing this, we’re defining our own “data specification”, as we need to remember the order in which the data is being written to the stream. We’ll need to read it back in the same order a little bit later.
Writing External Assets
For all externally defined content contained by our asset, we’ll want to make sure said data is written to the content pipeline using the ContentWriter.WriteExternalReference method.
This method takes an ExternalReference<TContent> instance as its sole argument. This instance should be the same one created by our SpriteSheetProcessor and passed to the ContextProcessorContext.BuildAsset<TInput,TOutput> method.
Luckily, our ContentItem<T> class stores those external references created when the nested builds for additional assets are initiated. So, by using the ContentItem<T>.GetReference method, we’ll get everything needed to easily write the external asset to the pipeline.
Simple Values Only, Please!
We are, for the most part, restricted to writing only value types to the content pipeline. You won’t be able to dump whole collections or lists of data onto the pipeline directly.
If you are dealing with arrays of data that need to be written, one technique you can use is to write an integer count for the number of items before iterating through and writing your array of junk.
If there is an inheritance hierarchy to our asset data, we can specify type information using enum values understood by both producer and consumer of pipeline data.
What a SpriteSheetWriter Looks Like
Let’s see how we do this with our Bad Echo Pipeline Extension code.
SpriteSheetWriter.cs
/// <summary>
/// Provides a writer of raw sprite sheet content into the content pipeline.
/// </summary>
[ContentTypeWriter]
public sealed class SpriteSheetWriter : ContentTypeWriter<SpriteSheetContent>
{
/// <inheritdoc />
public override string GetRuntimeReader(TargetPlatform targetPlatform)
=> typeof(SpriteSheetReader).AssemblyQualifiedName ?? string.Empty;
/// <inheritdoc />
protected override void Write(ContentWriter output, SpriteSheetContent value)
{
Require.NotNull(output, nameof(output));
Require.NotNull(value, nameof(value));
SpriteSheetAsset asset = value.Asset;
ExternalReference<Texture2DContent> textureReference
= value.GetReference<Texture2DContent>(asset.TexturePath);
output.WriteExternalReference(textureReference);
output.Write(asset.Rows);
output.Write(asset.Columns);
output.Write(asset.RowUp);
output.Write(asset.RowDown);
output.Write(asset.RowLeft);
output.Write(asset.RowRight);
output.Write(asset.RowInitial);
}
}
Who Is the Reader?
One of the required overrides is GetRuntimeReader, which asks us for the name of the assembly containing the content reader for the data.
I’m not a fan of magic strings that will cause runtime errors should any project-level settings happen to change (i.e. project/assembly name), so I make this implicit dependency official by actually grabbing the type information of a known reader and returning that.
Although it sounds backward, it’s a good practice for the data-producing pipeline extension to have a dependency on the data-consuming component.
It will prevent the game framework from ever forming an inappropriate dependency on pipeline extension code, and it allows for the extension to be able to communicate type information (when an inheritance hierarchy is present) using enum type identifying values defined and used by the consumer.
OK! That’s Enough Writing!
This pretty much takes care of everything on the pipeline extension library side of things. Now that we have data able to be written to the pipeline, we need to create some components that can read it.
The Reader
The job of the content reader is to read all of a previously written asset’s data from the content pipeline, and then use that to create an instance of the model type for the asset.
An asset’s model type is a functional class providing behaviors and the data that make the asset “do something” during runtime. Your standard, garden-variety type of domain model design.
The best class name for the asset model type should be the asset type’s name itself. So, in our case, our SpriteSheetReader will be returning a SpriteSheet.
Same as the Writer, Except We Reading!
Instead of a ContentWriter, we have a ContentReader, and instead of the all-encompassing Write method, we have a Read method for each of the supported value types.
For externally referenced assets, we can retrieve the model type for said asset by calling the ContentReader.ReadExternalReference<T> method.
What a SpriteSheetReader Looks Like
Let’s take a look.
SpriteSheetReader.cs
/// <summary>
/// Provides a reader of raw sprite sheet content from the content pipeline.
/// </summary>
public sealed class SpriteSheetReader : ContentTypeReader<SpriteSheet>
{
/// <inheritdoc />s
protected override SpriteSheet Read(ContentReader input, SpriteSheet existingInstance)
{
Require.NotNull(input, nameof(input));
var texture = input.ReadExternalReference<Texture2D>();
var rows = input.ReadInt32();
var columns = input.ReadInt32();
var rowUp = input.ReadInt32();
var rowDown = input.ReadInt32();
var rowLeft = input.ReadInt32();
var rowRight = input.ReadInt32();
var rowInitial = input.ReadInt32();
var spriteSheet = new SpriteSheet(texture, columns, rows);
spriteSheet.AddDirection(MovementDirection.None, rowInitial);
spriteSheet.AddDirection(MovementDirection.Up, rowUp);
spriteSheet.AddDirection(MovementDirection.Down, rowDown);
spriteSheet.AddDirection(MovementDirection.Left, rowLeft);
spriteSheet.AddDirection(MovementDirection.Right, rowRight);
return spriteSheet;
}
}
We read the values, initialize the model type, and then prime the model type’s behaviors. And now we have a sprite sheet!
There’s a Pipeline Extension for Ya
Hopefully, the sharing of my experiences in creating a pipeline extension for MonoGame is beneficial to you, the reader.
I’m still very new to MonoGame and game development in general; if any future “lessons learned” invalidate anything that I’ve written here, I’ll be sure to write about them.
Now get to extending that pipeline!
